Personal Informatics for Self-Regulated Learning
Ian Li
April 3, 2012
 Ryan Muller is a PhD student at the Human-Computer Interaction Institute at Carnegie Mellon University. He researches principles for designing technology that stimulates our intrinsic drive for mastery-based learning.
Ryan Muller is a PhD student at the Human-Computer Interaction Institute at Carnegie Mellon University. He researches principles for designing technology that stimulates our intrinsic drive for mastery-based learning.
Although the internet has fundamentally changed the speed and the scale of accessing information, that change has not seen such an impact in traditional forms of education. With popular new efforts like the video and exercise resource Khan Academy and online courses from Stanford (now spinning off into sites like Udemy and Coursera), people are talking about a revolution of personalized education — learners will be able to use computer-delivered content to learn at their own pace, whether supplementing schoolwork, developing job skills, or pursuing a hobby.
How personal informatics can help learning
There’s a problem here: learning on one’s own is not easy. Researchers have repeatedly found that people hold misconceptions about how to study well. For instance, rereading a passage gives the illusion of effective learning, but in reality quizzing oneself on the same material is far more effective for retention. Even then, people can misjudge the which items they will or will not be able to remember later.
The process of self-regulated learning works best when people accurately self-assess their learning and use that information to determine learning strategies and choose among resources. This reflective process fits well into the framework of personal informatics used already for applications like keeping up with one’s finances or making personal healthcare decisions.
For most people, their only experience quantifying learning is through grades on assignments and tests. While these can allow some level of reflection, the feedback loop is usually not tight enough. We are unable to fix our mistakes, making grades feel less like a opportunity for improvement and more like a final judgement.
How personal learning data can be collected
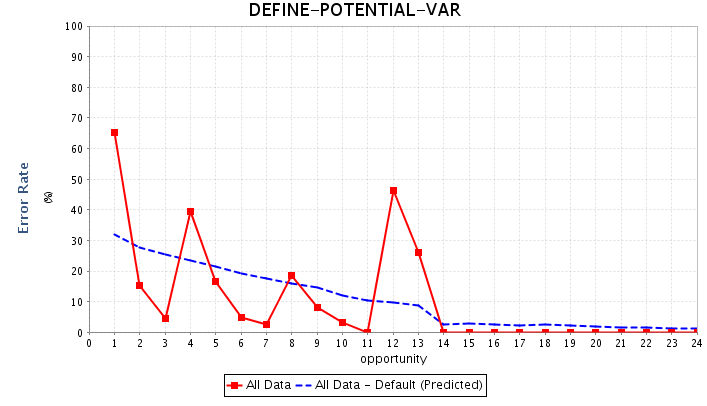
With computer-based practice, there is a great opportunity for timely personalized feedback. Several decades of research in the learning sciences have developed learner models for estimating a person’s knowledge of a topic based on their actions in a computer-based practice environment, often called an intelligent tutoring system. For example, a learner model for a physics tutor may predict the error rate of responses in defining the potential energy as a step in a physics problem — we see that the error rate decreases over the number of opportunities to use that skill, indicating learning (see below; from the PSLC DataShop). Such systems can not only track progress and give feedback but also make suggestions for effective learning strategies.
Our proposal envisions a web API that collects data from web-based learning resources into a personal central repository. Learner models analyze the data to provide quantified indicators of learning progress. The advantage of a central location is to compare and combine information across heterogeneous resources, as well as to enable self-experimentation with different types of learning interventions or strategies. Accumulation of enough data would allow findings to be shared among the community and give researchers access to data that could be used to improve learning. Finally, the API could also push back recommendations to the learning resources, taking advantage of the combined data and saving resource developers the difficulty of implementing learner model algorithms.
With personal informatics in learning, we see an opportunity not only for improving self-paced learning of more-or-less traditional content, but a grand vision of personalized learning: setting a vision of your future self, using the wealth of resources on the web to achieve your learning goals, and tracking your steps along the way.